
Introduction
In today’s data-driven world, organizations face the dual challenge of managing structured and unstructured data effectively while extracting meaningful insights. Leveraging Gen AI (Generative AI) with a Retrieval-Augmented Generation (RAG) framework provides an innovative solution. This blog explores how Gen AI multi-agent tooling streamlines data ingestion, retrieval, and insights generation across diverse datasets.
The Workflow
The presented solution integrates a seamless pipeline for handling both structured and unstructured data. Here's a breakdown of the process:
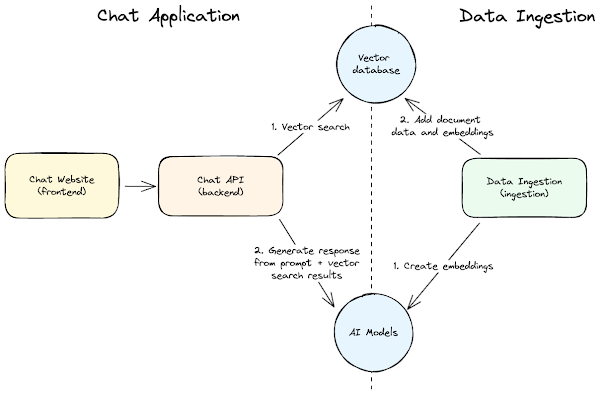
Data Ingestion via Upload Functionality
Users upload files containing structured data (e.g., JSON, CSV) or unstructured data (e.g., PDFs, documents). The system processes these inputs by:
- Chunking the data into manageable segments.
- Generating embeddings for each chunk to enable efficient semantic understanding.
Vector Storage
Embeddings are stored in a vector database for rapid retrieval. The architecture supports:
- OpenSearch for advanced search functionalities.
- Aurora PostgreSQL and pgvector for scalable and secure storage.
Data Retrieval via Gen AI Assist
Users query the system through natural language prompts. The process involves:
- Semantic Search to retrieve contextually relevant chunks.
- A Generative LLM (Large Language Model), which synthesizes responses based on retrieved data.
Multi-Agent Framework
The Gen AI Assist employs a multi-agent system to handle tasks, such as querying vector databases and fetching results via APIs, ensuring efficiency and modularity.
Want to explore what this could do for your business?
Talk to us